
Time Series Prediction Method Based on Simplified LSTM Neural Network
-
摘要:
针对标准长短期记忆(long short-term memory,LSTM)神经网络用于时间序列预测具有耗时长、复杂度高等问题,提出简化型LSTM神经网络并应用于时间序列预测.首先,通过耦合输入门与遗忘门实现对标准LSTM神经网络的结构简化;其次,从门结构控制方程中消除输入信号与偏差实现进一步精简;然后,采用梯度下降算法更新简化型LSTM神经网络的参数;最后,通过2个时间序列基准数据集及污水处理过程出水生化需氧量(biochemical oxygen demand,BOD)质量浓度预测进行实验验证.结果表明:在不显著降低预测精度的情况下,所设计的模型能够缩短训练时间,减少LSTM神经网络的计算复杂度,实现时间序列的预测.
Abstract:To solve the problem that the standard long short-term memory (LSTM) neural network is time consuming and has high complexity for time series prediction, a simplified LSTM neural network was proposed and it was applied to time series prediciton. First, the structure of the standard LSTM neural network was simplified by coupling input gate and forget gate. Second, the inputs and bias were removed from dynamic equation of the gates to further simplify the parameters. Third, the gradient descent algorithm was utilized to update the parameters of the simplified LSTM neural network. Finally, the validity of the proposed model was demonstrated by two time series benchmark problems and the prediction of biochemical oxygen demand (BOD) mass concentration in the wastewater treatment process. The experimental results show that the training time is shortened and the computational complexity is reduced without significantly reducing the prediction accuracy, which makes an efficient time series prediction.
-
时间序列预测可以判断事物发展趋势,高效的预测模型可为应用决策提供有力依据[1]. 长短期记忆(long short-term memory, LSTM)神经网络对时间序列预测具有显著优势[2-4],已广泛地应用于金融市场股票预测[5-7]、石油产量预测[8]、短时交通流预测[9]等领域,但标准LSTM神经网络用于时间序列预测具有耗时长、复杂度高等问题[10-11]. 围绕LSTM神经网络结构设计,目前已有大量学者进行了研究.
LSTM神经网络在训练过程中需要更新较多的参数,增加了训练时间[12],故对其内部结构进行删减尤为重要. 一些研究者通过简化LSTM神经网络结构提出了多种基于标准LSTM神经网络的简化变体[13],如去除遗忘门[14]、耦合输入门与遗忘门[15]、去除窥视孔连接[16]等. Greff等[13]对多种LSTM神经网络简化变体的效果进行了评价,实验证明耦合输入门与遗忘门、去除窥视孔连接的简化变体可以在不显著降低性能的情况下减少LSTM模型的参数数量和计算成本. Cho等[15]提出一种包括重置门与更新门2个门结构的门控循环单元(gated recurrent unit,GRU),实验证明GRU可以达到与LSTM模型相当的效果,并且能够很大程度上提高训练效率. Zhou等[17]提出只有一个门结构的最小门控单元(minimal gated unit,MGU),实验证明MGU具有与GRU相当的精度,但结构更简单,参数更少,训练速度更快. Oliver等[18]通过耦合输入门与遗忘门以简化LSTM模型,使用一个门结构同时控制遗忘和选择记忆,该神经网络与其他LSTM模型简化变体相比能够减少对历史数据的依赖性,降低网络的复杂度,在网络性能不变的情况下缩短训练时间[19]. 然而,以上介绍的LSTM简化模型,仍需要更新和存储较多的参数,导致网络计算冗余,训练时间较长.
针对以上问题,近几年一些学者提出精简门结构方程的方法,进一步减少训练过程中需要更新的参数,提高训练速度. Lu等[20]通过精简标准LSTM网络门结构方程减少参数更新,提出3个模型并将其与标准LSTM网络结构比较,实验证明该模型在较少参数的情况下可获得与标准LSTM模型相当的性能. Rahul等[21]通过减少重置门和更新门的参数,提出GRU的3种变体,并对其性能进行了评估. 结果表明,这些变体的性能与GRU模型相当,同时降低了计算开销. Joel等[22]介绍了MGU的3种模型变体,通过减少遗忘门动力方程中的参数数目,进一步简化了设计,这3种模型变体显示出与MGU模型相似的精度,同时使用较少的参数减少训练时间. 根据以上分析,在减少门结构数量的基础上精简门结构参数能够在保证网络性能的前提下减少网络的训练时间.
由于Oliver等[18]提出的LSTM简化神经网络具有较短训练时间、较少参数数量等优点,本文基于该网络提出简化型LSTM神经网络,在耦合门结构的基础上继续对门结构方程中的参数进行简化,可以更大程度上减少LSTM神经网络在训练过程中参数更新的数量,提高网络的训练速度. 通过2个基准数据集及污水处理过程出水生化需氧量(biochemical oxygen demand,BOD)质量浓度预测的实验验证,将其在3个时间序列数据集上与标准LSTM网络及其他变体进行比较评价,结果说明本文提出的简化型LSTM神经网络在训练时间减少的同时能够达到较好的时间序列预测精度.
1. 标准LSTM神经网络结构
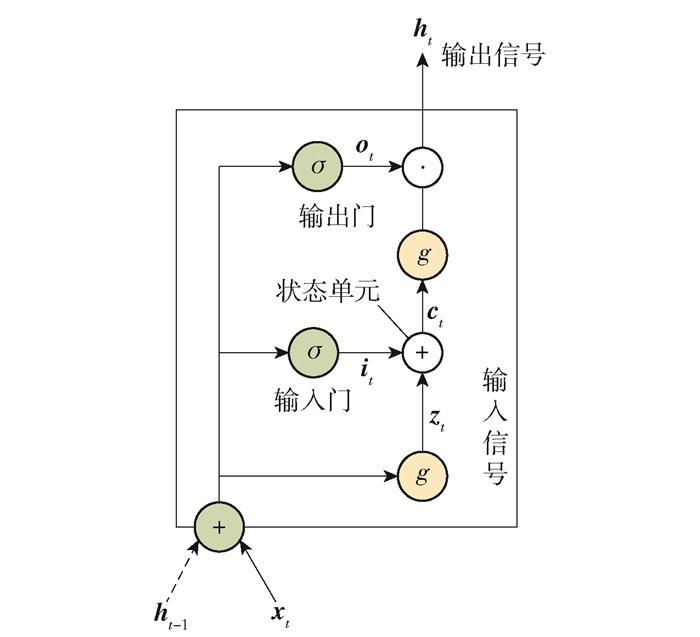
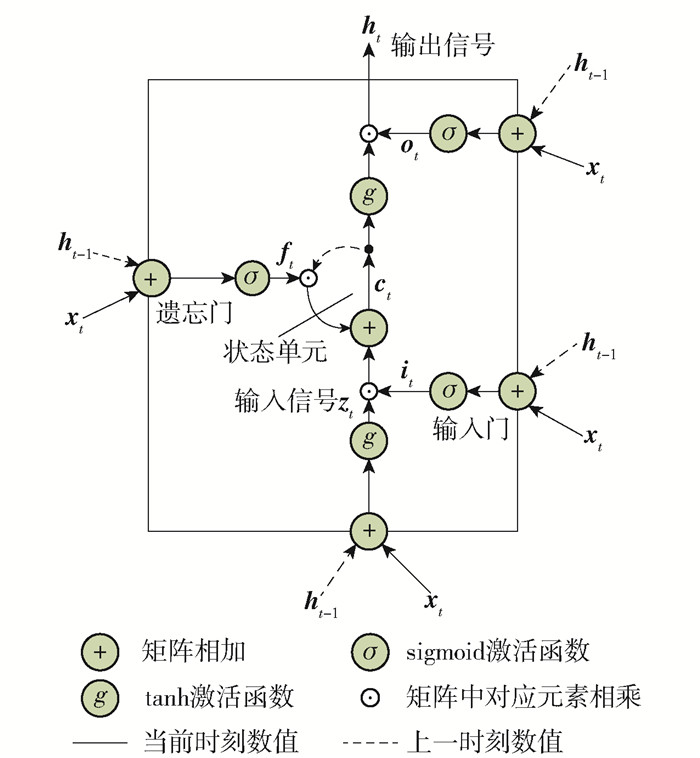
标准LSTM神经网络结构包含一个状态单元及3个门结构(输入门、遗忘门、输出门),其中状态单元用于记录当前时刻的状态,各门结构用于控制信息的遗忘或记忆. 本文介绍的LSTM模型的结构是去除窥视孔连接的标准LSTM模型[16],其内部结构图如图 1所示. 标准LSTM模型的结构为
$$ \left\{\begin{array}{l} \boldsymbol{z}_{t}=g\left(\boldsymbol{W}_{\boldsymbol{z}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{z}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{z}}\right) \\ \boldsymbol{i}_{t}=\sigma\left(\boldsymbol{W}_{\boldsymbol{i}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{i}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{i}}\right) \\ \boldsymbol{f}_{t}=\sigma\left(\boldsymbol{W}_{\boldsymbol{f}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{f}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{f}}\right) \\ \boldsymbol{c}_{t}=\boldsymbol{f}_{t} \odot \boldsymbol{c}_{t-1}+\boldsymbol{i}_{t} \odot \boldsymbol{z}_{t} \\ \boldsymbol{o}_{t}=\sigma\left(\boldsymbol{W}_{\boldsymbol{o}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{o}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{o}}\right) \\ \boldsymbol{h}_{t}=\boldsymbol{o}_{t} \odot g\left(\boldsymbol{c}_{t}\right) \end{array}\right. $$ (1) ![]() 图 1 LSTM神经网络内部结构详细示意图Figure 1. Detailed schematic diagram of the internal structure for LSTM neural network
图 1 LSTM神经网络内部结构详细示意图Figure 1. Detailed schematic diagram of the internal structure for LSTM neural network式中:xt为当前时刻输入向量;ht为当前时刻输出向量;zt、it、ft、ct、ot、ht分别为输入信号、输入门、遗忘门、状态单元、输出门、输出信号;Wz、Wi、Wf、Wo分别为zt、it、ft、ot中的输入权重矩阵;Uz、Ui、Uf、Uo分别为zt、it、ft、ot中的递归权重矩阵;bz、bi、bf、bo分别为zt、it、ft、ot中的偏置矩阵;σ为sigmoid激活函数;g为tanh激活函数;⊙表示矩阵点乘操作.
对于只有一个重复隐含状态的递归神经网络(recurrent neural network, RNN)结构,若设定m为输入向量的维度,n为隐含层单元的个数,则每次迭代过程需要更新的参数个数为(mn+n2+n). 由于标准LSTM神经网络存在3个门结构(输入门it、遗忘门ft、输出门ot)与输入信号zt,由式(1)可知,标准LSTM神经网络在每次迭代过程中需要更新的参数个数为4(mn+n2+n).
2. 简化型LSTM神经网络设计
本文提出的简化型LSTM神经网络,首先通过耦合输入门与遗忘门简化标准LSTM神经网络结构,其次对门结构方程中的参数进行精简以进一步减少网络参数,从而提高网络训练速度.
2.1 LSTM神经网络门结构简化设计
本文通过耦合输入门与遗忘门实现对标准LSTM神经网络的门结构简化,其结构由1个状态单元及2个门结构组成(如图 2所示),具体介绍如下.
1) 输入门:控制需要输入到网络中的信息,该结构与标准LSTM神经网络相同,通过
$$ \boldsymbol{z}_{t} =\sigma\left(\boldsymbol{W}_{\boldsymbol{z}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{z}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{z}}\right) $$ (2) $$ \boldsymbol{i}_{t} =\sigma\left(\boldsymbol{W}_{\boldsymbol{i}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{i}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{i}}\right) $$ (3) 实现.
2) 状态单元:状态单元ct结合输入信号zt与1-it控制的上一时刻的状态单元ct-1,其更新公式为
$$ \boldsymbol{c}_{t}=\left(1-\boldsymbol{i}_{t}\right) \odot \boldsymbol{c}_{t-1}+\boldsymbol{z}_{t} $$ (4) 由此可见,与标准LSTM神经网络不同,式(4)由1-it代替遗忘门ft对上一时刻的状态单元进行选择性记忆,当it数值为0时,上一时刻的单元状态全部记忆,当it数值为1时,上一时刻的单元状态全部遗忘,从而实现了输入门与遗忘门的耦合.
3) 输出门:控制当前时刻状态单元信息ct的输出程度,该结构与标准LSTM神经网络输出结构相同,通过
$$ \boldsymbol{o}_{t}=\sigma\left(\boldsymbol{W}_{\boldsymbol{o}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{o}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{o}}\right) $$ (5) $$ \boldsymbol{h}_{t}=\boldsymbol{o}_{t} \odot g\left(\boldsymbol{c}_{t}\right) $$ (6) 实现. 由此可见,输出门ot控制神经网络的最终输出. 若ot数值为0,则当前时刻单元状态ct全部不输出,ht输出值为0;若ot数值为1,则当前时刻单元状态ct全部输出.
经过输入门与遗忘门的耦合,LSTM网络在简化后由2个门结构组成,每次迭代过程需要更新的参数个数为3(mn+n2+n),与标准LSTM神经网络结构相比减少了25%.
2.2 LSTM神经网络门结构参数精简方法
虽然耦合输入门及遗忘门简化了标准LSTM神经网络的结构,然而在每次训练过程中均需对输入权重矩阵Wz、Wi、Wo进行更新,由此导致计算量较大,训练时间较长. 针对该问题,本文通过简化门结构方程的参数进一步对LSTM神经网络结构进行精简,在不损失精度的前提下缩短网络的训练时间.
本文主要通过2种方法精简门结构方程,包括:1) 去除输入权重矩阵Wi、Wo;2) 去除输入权重矩阵Wi、Wo与偏置矩阵bi、bo. 本文将经过以上2种形式简化后的LSTM神经网络分别简称为LSTM-简化型Ⅰ神经网络和LSTM-简化型Ⅱ神经网络,以下分别对这2种简化型LSTM神经网络进行介绍.
1) LSTM-简化型Ⅰ神经网络
该简化方法通过去除输入门与输出门中的输入权重矩阵Wi、Wo进一步简化LSTM神经网络,由
$$ \left\{\begin{array}{l} \boldsymbol{z}_{t}=g\left(\boldsymbol{W}_{\boldsymbol{z}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{z}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{z}}\right) \\ \boldsymbol{i}_{t}=\sigma\left(\boldsymbol{U}_{\boldsymbol{i}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{i}}\right) \\ \boldsymbol{c}_{t}=\left(1-\boldsymbol{i}_{t}\right) \odot \boldsymbol{c}_{t-1}+\boldsymbol{z}_{t} \\ \boldsymbol{o}_{t}=\sigma\left(\boldsymbol{U}_{\boldsymbol{o}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{\boldsymbol{o}}\right) \\ \boldsymbol{h}_{t}=\boldsymbol{o}_{t} \odot g\left(\boldsymbol{c}_{t}\right) \end{array}\right. $$ (7) 构成.
由此可见,与标准LSTM神经网络的门结构控制信号不同之处为:该网络门结构控制信号由t-1时刻输出信号ht-1、递归权重矩阵及偏置矩阵2项组成,在每次迭代过程中该网络需要更新的参数个数为3(mn+n2+n-2mn),降低了计算复杂度.
2) LSTM-简化型Ⅱ神经网络
该简化方法在去除输入门与输出门中输入权重矩阵Wi、Wo的同时,将偏置矩阵bi、bo去除,由
$$ \left\{\begin{array}{l} \boldsymbol{z}_{t}=g\left(\boldsymbol{W}_{\boldsymbol{z}} \boldsymbol{x}_{t}+\boldsymbol{U}_{\boldsymbol{z}} \boldsymbol{h}_{t-1}+\boldsymbol{b}_{z}\right) \\ \boldsymbol{i}_{t}=\sigma\left(\boldsymbol{U}_{\boldsymbol{i}} \boldsymbol{h}_{t-1}\right) \\ \boldsymbol{c}_{t}=\left(1-\boldsymbol{i}_{t}\right) \odot \boldsymbol{c}_{t-1}+\boldsymbol{z}_{t} \\ \boldsymbol{o}_{t}=\sigma\left(\boldsymbol{U}_{\boldsymbol{o}} \boldsymbol{h}_{t-1}\right) \\ \boldsymbol{h}_{t}=\boldsymbol{o}_{t} \odot g\left(\boldsymbol{c}_{t}\right) \end{array}\right. $$ (8) 构成.
由此可见,与标准LSTM神经网络的门结构控制信号不同之处为:该网络门结构控制信号仅由t-1时刻输出信号ht-1、递归权重矩阵1项组成,在每次迭代过程中该模型需要更新的参数个数为3(mn+n2+n-2mn-2n),进一步降低了LSTM神经网络的计算复杂度.
2.3 简化型LSTM神经网络学习算法
本文采用梯度下降算法[23-24]对提出的简化型LSTM神经网络的参数进行学习,定义损失函数计算公式为
$$ \boldsymbol{E}(t)=\frac{1}{2}\left(\boldsymbol{h}_{d, t}-\boldsymbol{h}_{t}\right)^{2} $$ (9) 式中:hd, t为网络在t时刻的期望输出;ht为网络在t时刻的实际输出.
下面以LSTM-简化型Ⅰ神经网络为例,介绍参数更新过程.
步骤1 根据
$$ \delta \boldsymbol{h}_{t}=\delta \boldsymbol{z}_{t+1} \boldsymbol{U}_{\boldsymbol{z}}+\delta \boldsymbol{i}_{t+1} \boldsymbol{U}_{\boldsymbol{i}}+\delta \boldsymbol{o}_{t+1} \boldsymbol{U}_{\boldsymbol{o}} $$ (10) $$ \delta \boldsymbol{z}_{t}=\delta \boldsymbol{h}_{t} \odot \boldsymbol{o}_{t} \odot g^{\prime}\left(\boldsymbol{c}_{t}\right) \odot \boldsymbol{i}_{t} \odot \boldsymbol{z}_{t}^{\prime} $$ (11) $$ \delta \boldsymbol{i}_{t}=\delta \boldsymbol{h}_{t} \odot \boldsymbol{o}_{t} \odot g^{\prime}\left(\boldsymbol{c}^{t}\right) \odot \boldsymbol{z}_{t} \odot \boldsymbol{i}_{t}^{\prime} $$ (12) $$ \delta \boldsymbol{o}_{t}=\delta \boldsymbol{h}_{t} \odot g\left(\boldsymbol{c}_{t}\right) \odot \boldsymbol{o}_{t}^{\prime} $$ (13) 计算t时刻输出值ht及输入信号zt、it、ot的误差项. 其中, 导数形式展开公式为
$$ g^{\prime}\left(\boldsymbol{c}_{t}\right) =1-g\left(\boldsymbol{c}_{t}\right)^{2} $$ (14) $$ \boldsymbol{z}_{t}^{\prime} =\boldsymbol{z}_{t}\left(1-\boldsymbol{z}_{t}\right) $$ (15) $$ \boldsymbol{i}_{t}^{\prime} =\boldsymbol{i}_{t}\left(1-\boldsymbol{i}_{t}\right) $$ (16) $$ \boldsymbol{o}_{t}^{\prime} =\boldsymbol{o}_{t}\left(1-\boldsymbol{o}_{t}\right) $$ (17) 步骤2 计算t时刻输入权重矩阵、递归权重矩阵、偏置矩阵的更新值公式为
$$ \delta \boldsymbol{W}_{\boldsymbol{z}, t}=\delta \boldsymbol{z}_{t} \otimes \boldsymbol{x}_{t} $$ (18) $$ \delta \boldsymbol{U}_{\boldsymbol{\varOmega}, t}=\delta \boldsymbol{\varOmega}_{t} \otimes \boldsymbol{h}_{t-1} $$ (19) $$ \delta \boldsymbol{b}_{\boldsymbol{\varOmega}, t}=\delta \boldsymbol{\varOmega}_{t} $$ (20) 式中:⊗为矩阵叉乘操作;Ω分别为{z, i, o}中的任意一个.
步骤3 根据
$$ \boldsymbol{W}_{\boldsymbol{z}, t} =\boldsymbol{W}_{\boldsymbol{z}, t+1}-\eta \times \delta \boldsymbol{W}_{\boldsymbol{z}, t} $$ (21) $$ \boldsymbol{U}_{\boldsymbol{\varOmega}, t} =\boldsymbol{U}_{\boldsymbol{\varOmega}, t+1}-\eta \times \delta \boldsymbol{U}_{\boldsymbol{\varOmega}, t} $$ (22) $$ \boldsymbol{b}_{\boldsymbol{\varOmega}, t} =\boldsymbol{b}_{\boldsymbol{\varOmega}, t+1}-\eta \times \delta \boldsymbol{b}_{\boldsymbol{\varOmega}, t} $$ (23) 计算t时刻更新后的输入权重矩阵、递归权重矩阵、偏置矩阵. 式中η为学习率.
步骤4 计算训练样本的均方根误差(root mean squared error, RMSE),如果训练样本的RMSE达到期望训练样本的RMSE或达到最大迭代次数,则参数更新结束,否则返回步骤1.
对于LSTM-简化型Ⅱ神经网络,由于其门结构方程在LSTM-简化型Ⅰ神经网络的基础上进一步去除了偏置矩阵,其权重矩阵更新与LSTM-简化型Ⅰ神经网络相同,如式(21)(22)所示.
3. 实验结果和分析
为了验证所提出的简化型LSTM神经网络在时间序列预测上的有效性,本文采用RMSE评价模型的预测准确性[25-27], 公式为
$$ \mathrm{RMSE}=\sqrt{\frac{\sum\limits_{t=1}^{N}\left(\boldsymbol{h}_{\mathrm{d}, t}-\boldsymbol{h}_{t}\right)^{2}}{N}} $$ (24) 式中N为样本个数. 将其与标准LSTM神经网络、只进行门结构简化的LSTM神经网络(简称LSTM-变体Ⅰ)、仅去除输入权重矩阵的LSTM神经网络(简称LSTM-变体Ⅱ)、仅去除输入权重矩阵与偏置矩阵的LSTM神经网络(简称LSTM-变体Ⅲ)等多种LSTM模型的性能进行比较,在参数设置(包括LSTM模型状态单元维度、学习率、期望训练样本的RMSE、迭代次数)相同的情况下分别计算训练和测试RMSE、训练时间及所需更新参数个数等,所有实验独立运行20次并求取均值.
3.1 时间序列基准数据集
在本节中采用2个时间序列基准数据集(Lorenz时间序列、Mackey-Glass时间序列)评估简化型LSTM神经网络的性能.
3.1.1 Lorenz时间序列预测
Lorenz系统是一种大气对流数学模型[28],它被广泛地用作时间序列预测的基准实验以评价模型的有效性. 其系统方程为
$$ \left\{\begin{array}{l} \frac{\mathrm{d} x(t)}{\mathrm{d} t}=a_{1} y(t)-a_{1} x(t) \\ \frac{\mathrm{d} y(t)}{\mathrm{d} t}=a_{2} x(t)-x(t) z(t)-y(t) \\ \frac{\mathrm{d} z(t)}{\mathrm{d} t}=x(t) y(t)-a_{3} z(t) \end{array}\right. $$ (25) 式中:x(t)、y(t)、z(t)为三维空间Lorenz系统的序列;a1、a2、a3为系统参数,a1=10,a2=28,a3=8/3.
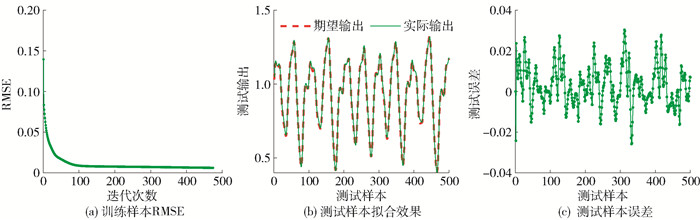
在本实验中,生成5 000组Lorenz样本, 仅使用y维样本y(t)进行时间序列预测. 前2 000组作为训练样本,后3 000组作为测试样本. 以[y(t) y(t-1) y(t-2)]为输入向量,预测y(t+1)的值. 设定状态单元维度为8,学习率η为0.01,期望训练样本的RMSE为0.060 0,最大迭代次数为1 000次. 当训练样本的RMSE达到期望训练样本的RMSE或最大迭代次数时,停止参数更新.
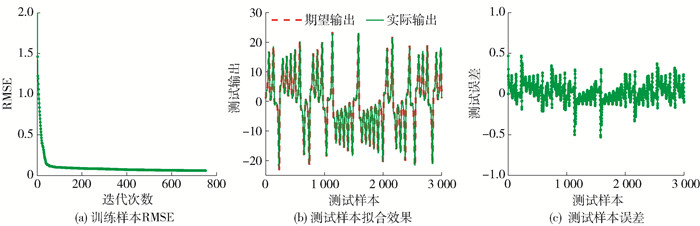
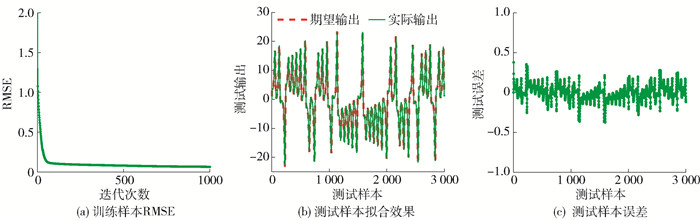
LSTM-简化型Ⅰ、Ⅱ的训练过程RMSE曲线分别如图 3、4中的(a)所示. 从图中可以看出,本文提出的简化型LSTM神经网络的训练RMSE可以快速收敛. 其测试结果如图 3、4中的(b)(c)所示,可以看出其均可以达到较好的拟合效果.
![]() 图 3 LSTM-简化型Ⅰ对Lorenz时间序列预测的训练过程及测试效果Figure 3. Training process and testing results for the simplified LSTM Ⅰ in Lorenz time series
图 3 LSTM-简化型Ⅰ对Lorenz时间序列预测的训练过程及测试效果Figure 3. Training process and testing results for the simplified LSTM Ⅰ in Lorenz time series![]() 图 4 LSTM-简化型Ⅱ对Lorenz时间序列预测的训练过程及测试效果Figure 4. Training process and testing results for the simplified LSTM Ⅱ in Lorenz time series
图 4 LSTM-简化型Ⅱ对Lorenz时间序列预测的训练过程及测试效果Figure 4. Training process and testing results for the simplified LSTM Ⅱ in Lorenz time series表 1对比了不同模型的性能,可以看出,(LSTM-变体Ⅰ)或(LSTM-变体Ⅱ、Ⅲ)均可以减少更新参数个数并缩短训练时间,但LSTM-变体Ⅰ、Ⅱ的训练时间短于LSTM-变体Ⅲ,同时LSTM-简化型Ⅰ在需要更新的参数个数比LSTM-变体Ⅲ较多的情况下训练时间显著缩短,均说明门结构精简相对于简化门结构方程对简化LSTM神经网络的效果更显著. 通过实验结果分析可以得出,本文提出的LSTM-简化型Ⅰ、Ⅱ神经网络能够在不显著降低预测精度的情况下,进一步缩短训练时间,减少LSTM神经网络的计算复杂度,减少预测时间,更易对时间序列信息预测.
表 1 Lorenz时间序列预测模型性能对比Table 1. Performance comparison of different models for Lorenz time series模型 RMSE 训练时间/s 更新参数个数 训练样本 测试样本 标准LSTM 0.060 0 0.079 3 98.67 384 LSTM-变体Ⅰ 0.060 0 0.074 1 73.91 288 LSTM-变体Ⅱ 0.060 0 0.073 3 72.68 192 LSTM-变体Ⅲ 0.060 0 0.070 8 92.62 128 LSTM-简化型Ⅰ 0.060 0 0.075 2 58.68 144 LSTM-简化型Ⅱ 0.066 0 0.078 1 69.05 96 注:黑体代表本文提出的简化型LSTM模型. 3.1.2 Mackey-Glass时间序列预测
Mackey-Glass时间序列预测问题已被公认为评估网络性能的基准问题之一[29]. 时间序列预测由离散方程
$$ x(t+1)=(1-a) x(t)+\frac{b x(t-\tau)}{1+x^{10}(t-\tau)} $$ (26) 产生. 式中: a=0.1, b=0.2, τ=17, x(0)=1.2.
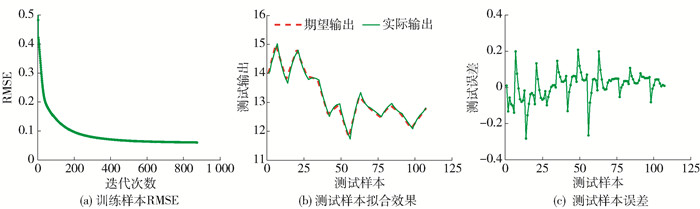
在本实验中,选取样本1 000组,其中前500组作为训练样本, 后500组作为测试样本. 以[x(t) x(t-6) x(t-12) x(t-18)]为输入向量,预测x(t+6)的值. 设定状态单元维度为10,学习率η为0.01,期望训练RMSE为0.006 0,最大迭代次数为700次. 当训练样本的RMSE达到期望训练样本的RMSE或最大迭代次数时,停止参数更新.
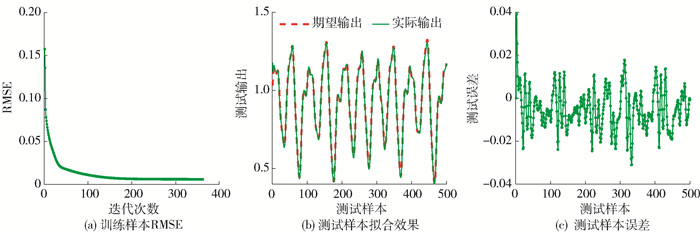
LSTM-简化型Ⅰ、Ⅱ的训练过程分别如图 5、6中的(a)所示. 从图中可以看出,训练RMSE可以达到期望训练RMSE. 测试结果、测试误差分别如图 5、6中的(b)(c)所示,从图中可以看出,本文提出的简化型LSTM神经网络的测试结果可以达到较好的拟合效果.
![]() 图 5 LSTM-简化型Ⅰ对Mackey-Glass时间序列预测的训练过程及测试效果Figure 5. Training process and testing results for the simplified LSTMⅠ in Mackey-Glass time series
图 5 LSTM-简化型Ⅰ对Mackey-Glass时间序列预测的训练过程及测试效果Figure 5. Training process and testing results for the simplified LSTMⅠ in Mackey-Glass time series![]() 图 6 LSTM-简化型Ⅱ对Mackey-Glass时间序列预测的训练过程及测试效果Figure 6. Training process and testing results for the simplified LSTMⅡ in Mackey-Glass time series
图 6 LSTM-简化型Ⅱ对Mackey-Glass时间序列预测的训练过程及测试效果Figure 6. Training process and testing results for the simplified LSTMⅡ in Mackey-Glass time series从表 2对不同模型进行比较的结果可以看出,3种LSTM变体(LSTM-变体Ⅰ、Ⅱ、Ⅲ)通过对门结构精简或简化门结构方程的方式,均缩短了训练时间,并且LSTM-变体Ⅰ在需要更新的参数个数比LSTM-变体Ⅱ、Ⅲ较多的情况下训练时间缩短,同时LSTM-简化型Ⅰ、LSTM-变体Ⅲ均可以减少更新参数个数并缩短训练时间,但前者的训练时间短于后者,说明门结构精简相对于简化门结构方程对简化LSTM神经网络的效果更显著. 通过实验结果分析,可以得出,本文提出的LSTM-简化型Ⅰ、Ⅱ神经网络在不显著降低预测精度的情况下进一步缩短训练时间,在时间序列预测过程中达到对时间序列信息简洁、快速预测的目的.
表 2 Mackey-Glass时间序列预测模型性能对比Table 2. Performance comparison of different models for Mackey-Glass time series模型 RMSE 训练时间/s 更新参数个数 训练样本 测试样本 标准LSTM 0.006 0 0.007 1 55.27 600 LSTM-变体Ⅰ 0.006 0 0.007 2 38.11 450 LSTM-变体Ⅱ 0.006 0 0.006 6 38.63 280 LSTM-变体Ⅲ 0.006 0 0.006 5 43.64 200 LSTM-简化型Ⅰ 0.006 0 0.007 0 18.33 210 LSTM-简化型Ⅱ 0.006 0 0.007 1 21.58 150 注:黑体代表本文提出的简化型LSTM模型. 3.2 污水处理中BOD预测
BOD是污水处理中评价水质的重要指标之一, 具有高度的非线性、大时变的特征,很难及时准确地预测其质量浓度[30].本文利用LSTM-简化型Ⅰ、Ⅱ神经网络对污水处理过程中的BOD进行建模,选取前8时刻的BOD质量浓度作为输入向量,下一时刻的BOD质量浓度作为输出变量.
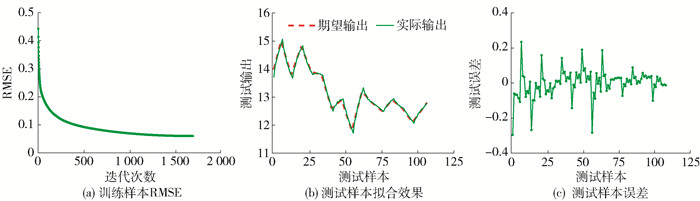
选取北京市某污水厂的数据进行仿真,获得357组按照时间顺序进行排列的样本,选取前250组作为训练样本,后107组作为测试样本,将所有样本归一化至[-1, 1]输入模型,并将样本反归一化后输出. 设定状态单元维度为15,学习率η为0.01,期望训练样本的RMSE为0.060 0,最大迭代次数为2 000次. 当训练样本的RMSE达到期望训练样本的RMSE或最大迭代次数时,停止参数更新.
LSTM-简化型Ⅰ、Ⅱ的训练过程分别如图 7、8中的(a)所示. 从图中可以看出,训练样本的RMSE能够达到期望训练样本的RMSE. 其测试结果反归一化后输出并计算测试误差,分别如图 7、8中的(b)(c)所示. 从图中可以看出,简化型LSTM神经网络的测试结果均可以达到较好的拟合效果.
![]() 图 7 LSTM-简化型Ⅰ对BOD质量浓度预测的训练过程及测试效果Figure 7. Training process and testing results for the simplified LSTMⅠ in BOD mass concentration prediction
图 7 LSTM-简化型Ⅰ对BOD质量浓度预测的训练过程及测试效果Figure 7. Training process and testing results for the simplified LSTMⅠ in BOD mass concentration prediction![]() 图 8 LSTM-简化型Ⅱ对BOD质量浓度预测的训练过程及测试效果Figure 8. Training process and testing results for the simplified LSTMⅡ in BOD mass concentration prediction
图 8 LSTM-简化型Ⅱ对BOD质量浓度预测的训练过程及测试效果Figure 8. Training process and testing results for the simplified LSTMⅡ in BOD mass concentration prediction从表 3的对比结果可以看出,在达到期望训练样本的RMSE、停止参数更新的情况下,LSTM-变体Ⅰ比LSTM-变体Ⅱ、Ⅲ需要更新较多的参数个数但需要较短的训练时间,同时LSTM-简化型Ⅰ在需要更新的参数个数与LSTM-变体Ⅲ相同的情况下训练时间显著缩短,均说明门结构精简对简化LSTM神经网络的效果更显著. 通过实验结果分析可以得出,本文提出的LSTM-简化型Ⅰ、Ⅱ神经网络能够在精度相当的情况下进一步缩短训练时间,对BOD质量浓度快速预测.
表 3 BOD质量浓度预测模型性能对比Table 3. Performance comparison of different models for BOD mass concentration prediction模型 RMSE 训练时间/s 更新参数个数 训练样本 测试样本 标准LSTM 0.060 0.059 99.35 1 440 LSTM-变体Ⅰ 0.060 0.064 30.11 1 080 LSTM-变体Ⅱ 0.060 0.063 51.93 480 LSTM-变体Ⅲ 0.060 0.066 62.75 360 LSTM-简化型Ⅰ 0.060 0.062 14.44 360 LSTM-简化型Ⅱ 0.060 0.065 29.98 270 注:黑体代表本文提出的简化型LSTM模型. 4. 结论
1) 简化型LSTM神经网络能够在不显著降低模型精度的情况下减少计算复杂度,缩短训练时间.
2) 基于简化型LSTM神经网络的时间序列预测方法能够实现时间序列的高效预测.
-
![]()
图 1 LSTM神经网络内部结构详细示意图
Figure 1. Detailed schematic diagram of the internal structure for LSTM neural network
![]()
图 3 LSTM-简化型Ⅰ对Lorenz时间序列预测的训练过程及测试效果
Figure 3. Training process and testing results for the simplified LSTM Ⅰ in Lorenz time series
![]()
图 4 LSTM-简化型Ⅱ对Lorenz时间序列预测的训练过程及测试效果
Figure 4. Training process and testing results for the simplified LSTM Ⅱ in Lorenz time series
![]()
图 5 LSTM-简化型Ⅰ对Mackey-Glass时间序列预测的训练过程及测试效果
Figure 5. Training process and testing results for the simplified LSTMⅠ in Mackey-Glass time series
![]()
图 6 LSTM-简化型Ⅱ对Mackey-Glass时间序列预测的训练过程及测试效果
Figure 6. Training process and testing results for the simplified LSTMⅡ in Mackey-Glass time series
![]()
图 7 LSTM-简化型Ⅰ对BOD质量浓度预测的训练过程及测试效果
Figure 7. Training process and testing results for the simplified LSTMⅠ in BOD mass concentration prediction
![]()
图 8 LSTM-简化型Ⅱ对BOD质量浓度预测的训练过程及测试效果
Figure 8. Training process and testing results for the simplified LSTMⅡ in BOD mass concentration prediction
表 1 Lorenz时间序列预测模型性能对比
Table 1 Performance comparison of different models for Lorenz time series
模型 RMSE 训练时间/s 更新参数个数 训练样本 测试样本 标准LSTM 0.060 0 0.079 3 98.67 384 LSTM-变体Ⅰ 0.060 0 0.074 1 73.91 288 LSTM-变体Ⅱ 0.060 0 0.073 3 72.68 192 LSTM-变体Ⅲ 0.060 0 0.070 8 92.62 128 LSTM-简化型Ⅰ 0.060 0 0.075 2 58.68 144 LSTM-简化型Ⅱ 0.066 0 0.078 1 69.05 96 注:黑体代表本文提出的简化型LSTM模型.  下载: 导出CSV
下载: 导出CSV
表 2 Mackey-Glass时间序列预测模型性能对比
Table 2 Performance comparison of different models for Mackey-Glass time series
模型 RMSE 训练时间/s 更新参数个数 训练样本 测试样本 标准LSTM 0.006 0 0.007 1 55.27 600 LSTM-变体Ⅰ 0.006 0 0.007 2 38.11 450 LSTM-变体Ⅱ 0.006 0 0.006 6 38.63 280 LSTM-变体Ⅲ 0.006 0 0.006 5 43.64 200 LSTM-简化型Ⅰ 0.006 0 0.007 0 18.33 210 LSTM-简化型Ⅱ 0.006 0 0.007 1 21.58 150 注:黑体代表本文提出的简化型LSTM模型.
下载: 导出CSV
表 3 BOD质量浓度预测模型性能对比
Table 3 Performance comparison of different models for BOD mass concentration prediction
模型 RMSE 训练时间/s 更新参数个数 训练样本 测试样本 标准LSTM 0.060 0.059 99.35 1 440 LSTM-变体Ⅰ 0.060 0.064 30.11 1 080 LSTM-变体Ⅱ 0.060 0.063 51.93 480 LSTM-变体Ⅲ 0.060 0.066 62.75 360 LSTM-简化型Ⅰ 0.060 0.062 14.44 360 LSTM-简化型Ⅱ 0.060 0.065 29.98 270 注:黑体代表本文提出的简化型LSTM模型.
下载: 导出CSV
-
[1] TANG X, LI C, BAO Y. Seasonal forecasting of agriculturalcommodity price using a hybrid STL and ELM method: evidence from the vegetable market in China[J]. Neurocomputing, 2018, 275: 2831-2844. doi: 10.1016/j.neucom.2017.11.053
[2] SPECHT D F. A general regression neural network[J]. IEEE Transactions on Neural Networks, 1991, 2(6): 568-576. doi: 10.1109/72.97934
[3] BENGIO Y, SIMARD P, FRASCONI P. Learning long-term dependencies with gradient descent is difficult[J]. IEEE Transactions on Neural Networks, 1994, 5(2): 157-166. doi: 10.1109/72.279181
[4] HOCHREITER S, SCHMIDHUBER J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. doi: 10.1162/neco.1997.9.8.1735
[5] FISCHER T, KRAUSS C. Deep learning with long short-term memory networks for financial market predictions[J]. European Journal of Operational Research, 2017, 270(2): 654-669. http://www.researchgate.net/publication/321630147_Deep_learning_with_long_short-term_memory_networks_for_financial_market_predictions
[6] YAN H J, OUYANG H B. Financial time series prediction based on deep learning[J]. Wireless Personal Communications, 2018, 102(2): 683-700. doi: 10.1007/s11277-017-5086-2
[7] 史建楠, 邹俊忠, 张见, 等. 基于DMD-LSTM模型的股票价格时间序列预测研究[J]. 计算机应用研究, 2020, 37(3): 662-666. https://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ202003005.htm SHI J N, ZOU J Z, ZHANG J, et al. Research of stock price prediction based on DMD-LSTM model [J]. Application Research of Computers, 2020, 37(3): 662-666. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JSYJ202003005.htm
[8] SAGHEER A, KOTB M. Time series forecasting of petroleum production using deep LSTM recurrent networks[J]. Neurocomputing, 2018, 323: 203-213. http://www.zhangqiaokeyan.com/academic-journal-foreign_other_thesis/0204112744957.html
[9] 罗向龙, 李丹阳, 杨彧, 等. 基于KNN-LSTM的短时交通流预测[J]. 北京工业大学学报, 2018, 44(12): 1521-1527. doi: 10.11936/bjutxb2018030029 LUO X L, LI D Y, YANG Y, et al. Short-term traffic flow prediction based on KNN-LSTM[J]. Journal of Beijing University of Technology, 2018, 44(12): 1521-1527. (in Chinese) doi: 10.11936/bjutxb2018030029
[10] BANDARA K, BERGMEIR C, HEWAMALAGE H. LSTM-MSNet: leveraging forecasts on sets of related time series with multiple seasonal patterns[J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(4): 1586-1599. doi: 10.1109/TNNLS.2020.2985720
[11] 葛瑞, 王朝晖, 徐鑫, 等. 基于多层卷积神经网络特征和双向长短时记忆单元的行为识别[J]. 控制理论与应用, 2017, 34(6): 790-796. https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201706013.htm GE R, WANG Z H, XU X, et al. Action recognition with hierarchical convolutional neural networks features and bi-directional long short-term memory model[J]. Control Theory & Applications, 2017, 34(6): 790-796. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201706013.htm
[12] HOUDT G V, MOSQUERA C, GONZALO N. A review on the long short-term memory model[J]. Artificial Intelligence Review, 2020(53): 5929-5955. doi: 10.1007/s10462-020-09838-1
[13] GREFF K, SRIVASTAVA R K, JAN K. LSTM: a search space odyssey[J]. IEEE Transactions on Neural Networks & Learning Systems, 2016, 28(10): 2222-2232. http://www.ncbi.nlm.nih.gov/pubmed/27411231
[14] 陈宙斯, 胡文心. 简化LSTM的语音合成[J]. 计算机工程与应用, 2018, 54(3): 131-135. https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201803021.htm CHEN Z S, HU W X. Speech synthesis using simplified LSTM[J]. Computer Engineering and Applications, 2018, 54(3): 131-135. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-JSGG201803021.htm
[15] CHO K, VAN MERRIENBOER B, BAHDANAU D, et al. On the properties of neural machine translation: encoder-decoder approaches [EB/OL]. [2020-06-27]. https://arxiv.org/abs/1409.1259.
[16] GERS F A, SCHRAUDOLPH N N. Learning precise timing with LSTM recurrent networks[J]. Journal of Machine Learning Research, 2003, 3(1): 115-143. http://portal.acm.org/citation.cfm?id=944919.944925
[17] ZHOU G B, WU J X, ZHANG C L, et al. Minimal gated unit for recurrent neural networks[J]. International Journal of Automation and Computing, 2016, 13(3): 226-234. doi: 10.1007/s11633-016-1006-2
[18] OLIVER O, RODRIGUEZ A. Simplified LSTM unit and search space probability exploration for image description[C]//IEEE International Conference on Information. Piscataway: IEEE, 2016: 1-5.
[19] CHUNG J, GULCEHRE C, CHO K, et al. Empirical evaluation of gated recurrent neural networks on sequence modeling [EB/OL]. [2020-07-30]. https://arxiv.org/abs/1412.3555.
[20] LU Y Z, SALEM F M. Simplified gating in long short-term memory (LSTM) recurrent neural networks[EB/OL]. [2020-08-12]. https://arxiv.org/abs/1701.03441.
[21] RAHUL D, FATHI M. Gate-variants of gated recurrent unit (GRU) neural networks[C] //IEEE International Midwest Symposium on Circuits and Systems. Piscataway: IEEE, 2017: 1597-1600.
[22] JOEL C, FATHI M. Simplified minimal gated unit variations for recurrent neural networks[C]//IEEE International Midwest Symposium on Circuits and Systems. Piscataway: IEEE, 2017: 1593-1596.
[23] GRAVES A, MOHAMED A R, HINTON G. Speech recognition with deep recurrent neural networks[C]//2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2013: 6645-6649.
[24] WERBOS P J. Backpropagation through time: what it does and how to do it[J]. Proceedings of the IEEE, 1990, 78(10): 1550-1560. doi: 10.1109/5.58337
[25] RODRIGUES F, MARKOU I, PEREIRA F C. Combining time-series and textual data for taxi demand prediction in event areas: a deep learning approach[J]. Information Fusion, 2019, 49: 120-129. doi: 10.1016/j.inffus.2018.07.007
[26] YANG J, GUO Y, ZHAO W. Long short-term memory neural network based fault detection and isolation for electro-mechanical actuators[J]. Neurocomputing, 2019, 360: 85-96. doi: 10.1016/j.neucom.2019.06.029
[27] HONG J, WANG Z, YAO Y. Fault prognosis of battery system based on accurate voltage abnormity prognosis using long short-term memory neural networks[J]. Applied Energy, 2019, 251: 1-14. http://www.sciencedirect.com/science/article/pii/S0306261919310554
[28] CHEN H, GONG Y, HONG X. Online modeling with tunable RBF network[J]. IEEE Transactions on Cybernetics, 2013, 43(3): 935-947. doi: 10.1109/TSMCB.2012.2218804
[29] QIAO J F, HAN H G. Identification and modeling of nonlinear dynamical systems using a novel self-organizing RBF-based approach[J]. Automatica, 2012, 48(8): 1729-1734. doi: 10.1016/j.automatica.2012.05.034
[30] 韩改堂, 乔俊飞, 韩红桂. 基于自适应递归模糊神经网络的污水处理控制[J]. 控制理论与应用, 2016, 33(9): 1252-1258. https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201609015.htm HAN G T, QIAO J F, HAN H G. Wastewater treatment control method based on adaptive recurrent fuzzy neural network [J]. Control Theory & Applications, 2016, 33(9): 1252-1258. (in Chinese) https://www.cnki.com.cn/Article/CJFDTOTAL-KZLY201609015.htm
-
期刊类型引用(17)
1. 杨彦霞,王普,高学金,高慧慧,齐泽洋. 基于混合双层自组织径向基函数神经网络的优化学习算法. 北京工业大学学报. 2024(01): 38-49 .  本站查看
本站查看
2. 肖志良,汪丽娟,郑雁予. 基于LSTM模型的工业物联网通信缺失数据预测研究. 电子元器件与信息技术. 2024(02): 164-167 . 百度学术
3. 吴宇轩,虞慧群,范贵生. 基于误差补偿的多模态协同交通流预测模型. 电子学报. 2024(08): 2878-2890 . 百度学术
4. 刘佳,李静,穆秋燃,武哲志. 基于互信息粒子群优化-长短期记忆神经网络医疗设备运行质量预测模型的慢性呼吸系统疾病诊疗设备智能管理研究. 中国医学装备. 2024(09): 107-112 . 百度学术
5. 陈家乐,张芸芸,崔红伟. 基于LSTM神经网络的办公建筑逐日能耗预测研究. 建筑节能(中英文). 2024(09): 74-78 . 百度学术
6. 唐维,陶钰欣,郝启文,庞中华. 基于遗传算法优化BP神经网络的曝气量预测. 控制工程. 2024(10): 1746-1752 . 百度学术
7. 肖克,张建军,谭文武,王理,宋玲毓,林海军. 融合Prophet与PCA技术的CNN-LSTM模型在水质预测中的应用. 计量科学与技术. 2024(10): 38-44 . 百度学术
8. 杜先君,柴俊伟. 基于优化特征选择的污水处理过程BOD神经网络软测量模型. 兰州理工大学学报. 2024(06): 85-91 . 百度学术
9. 韩雅萱,石梦舒,黄元生,刘敦楠,段文军. 基于机器学习的短期电力负荷预测方法比较及改进研究. 科技管理研究. 2023(01): 163-170 . 百度学术
10. 张多纳,赵宏佳,鲁远耀,张宝昌. 电磁信号调制方式识别:现状、方法和展望. 信息与控制. 2023(01): 59-74 . 百度学术
11. 熊思亦,熊永良. 基于CEEMDAN-LSTM组合方法的海平面变化预测分析. 大地测量与地球动力学. 2023(09): 899-903 . 百度学术
12. 张泽龙,韦冬妮,唐梦媛,纪强,杨燕. 基于改进LSTM的电力负荷预测与成本感知优化策略研究. 电子设计工程. 2023(21): 132-136 . 百度学术
13. 彭路,柳俊凯,盛爱晶,张兴海,孙文正. 基于LSTM的机场跑道视程预测. 计算机系统应用. 2022(05): 203-212 . 百度学术
14. 刘兴华,耿晨,谢胜寒,田佳强,曹晖. 考虑光伏发电不确定性的日前火电-光伏经济调度. 系统仿真学报. 2022(08): 1874-1884 . 百度学术
15. 胡赛,周庆燕,李号,邵继. 基于ARIMA-LSTM的服装流行趋势预测模型. 工业控制计算机. 2022(08): 115-117 . 百度学术
16. 许自舟,李亚芳,程嘉熠,吉志新,张晓霞,林建国. 天津市近岸海域水质变化趋势分析及水质目标研究. 环境工程技术学报. 2022(05): 1378-1388 . 百度学术
17. 苏万斌,江叶峰,徐彪,易灿灿. 基于Encoder-Decoder LSTM的电梯制动滑移量预测方法研究. 机械制造与自动化. 2022(06): 28-31 . 百度学术
其他类型引用(27)
计量
- 文章访问数: 419
- HTML全文浏览量: 21
- PDF下载量: 98
- 被引次数: 44
